Análisis de Crecimiento Poblacional en Centros Poblados del Perú
Paul Efren Santos Andrade
2026-01-15
Source:vignettes/centros-poblados-crecimiento.Rmd
centros-poblados-crecimiento.RmdIntroducción
La función get_centros_poblados_crecimiento() del
paquete rsdot proporciona acceso programático a datos de
centros poblados del Perú con información detallada sobre su tasa de
crecimiento poblacional del período intercensal 2007-2017.
Esta viñeta demuestra cómo utilizar la función para realizar análisis demográficos y espaciales, desde la descarga básica de datos hasta visualizaciones avanzadas.
Uso básico
Ver departamentos disponibles
Para conocer qué departamentos están disponibles, ejecuta la función sin argumentos:
Esto mostrará una lista de los 25 departamentos del Perú disponibles.
Cargar datos de un departamento
Carguemos los datos de centros poblados del departamento de Cusco:
ccpp_cusco <- get_centros_poblados_crecimiento(departamento = "CUSCO")
# Explorar la estructura de los datos
glimpse(ccpp_cusco)
#> Rows: 837
#> Columns: 15
#> $ nro <chr> "4,869", "5,108", "5,428", "5,290", "5,431", "4,839", "4,79…
#> $ codccpp <chr> "0804010043", "0807070055", "0812070001", "0810060001", "08…
#> $ ubigeo <chr> "080401", "080707", "081207", "081006", "081207", "080304",…
#> $ dep <chr> "CUSCO", "CUSCO", "CUSCO", "CUSCO", "CUSCO", "CUSCO", "CUSC…
#> $ prov <chr> "CALCA", "CHUMBIVILCAS", "QUISPICANCHI", "PARURO", "QUISPIC…
#> $ distrito <chr> "CALCA", "QUIÑOTA", "HUARO", "OMACHA", "HUARO", "CHINCHAYPU…
#> $ centro_pob <chr> "YANAHUAYLLA", "CENTRO", "HUARO", "OMACHA", "URPAY", "SUMAR…
#> $ pob_2007 <chr> "209", "202", "1,420", "398", "404", "237", "6,652", "147",…
#> $ pob_2017 <chr> "211", "210", "1,833", "391", "402", "237", "10,182", "155"…
#> $ tasa <dbl> 0.10, 0.39, 2.59, -0.18, -0.05, 0.00, 4.35, 0.53, 0.65, -1.…
#> $ capital <chr> "No es capital", "No es capital", "Distrital", "Distrital",…
#> $ region <chr> "Sierra", "Sierra", "Sierra", "Sierra", "Sierra", "Sierra",…
#> $ urb_rural <chr> "RURAL", "RURAL", "RURAL", "RURAL", "RURAL", "RURAL", "URBA…
#> $ tc_catg <chr> "POSITIVO", "POSITIVO", "POSITIVO", "NEGATIVO", "NEGATIVO",…
#> $ geom <POINT [°]> POINT (-71.93249 -13.29263), POINT (-72.11369 -14.285…Estructura de los datos
Los datos incluyen las siguientes variables:
-
nro: Número de identificación -
codccpp: Código del centro poblado -
ubigeo: Código UBIGEO del distrito -
dep: Departamento -
prov: Provincia -
distrito: Distrito -
centro_pob: Nombre del centro poblado -
pob_2007: Población en el censo 2007 -
pob_2017: Población en el censo 2017 -
tasa: Tasa media de crecimiento anual (%) -
capital: Tipo de capital (Departamental, Provincial, Distrital, No es capital) -
region: Región natural (Costa, Sierra, Selva) -
urb_rural: Clasificación urbano/rural -
tc_catg: Categoría de tasa de crecimiento (POSITIVO, NEGATIVO) -
geom: Geometría tipo POINT (coordenadas)
Filtrado de datos
Filtrado por provincia
Podemos filtrar los datos por provincia:
ccpp_prov_cusco <- get_centros_poblados_crecimiento(
departamento = "CUSCO",
provincia = "CUSCO"
)
nrow(ccpp_prov_cusco)
#> [1] 37Filtrado por distrito
Para obtener centros poblados de un distrito específico:
ccpp_anta <- get_centros_poblados_crecimiento(
departamento = "CUSCO",
provincia = "ANTA"
)Múltiples departamentos
La función permite cargar varios departamentos simultáneamente:
ccpp_sur <- get_centros_poblados_crecimiento(
departamento = c("CUSCO", "PUNO", "AREQUIPA")
)
# Ver distribución por departamento y categoría
ccpp_sur |>
st_drop_geometry() |>
count(dep, tc_catg)
#> # A tibble: 6 × 3
#> dep tc_catg n
#> <chr> <chr> <int>
#> 1 AREQUIPA NEGATIVO 144
#> 2 AREQUIPA POSITIVO 151
#> 3 CUSCO NEGATIVO 412
#> 4 CUSCO POSITIVO 425
#> 5 PUNO NEGATIVO 597
#> 6 PUNO POSITIVO 322Análisis descriptivo
Top 10 por crecimiento
# Centros poblados con mayor crecimiento
top_crecimiento <- ccpp_cusco |>
arrange(desc(tasa)) |>
head(10) |>
st_drop_geometry() |>
select(centro_pob, distrito, pob_2007, pob_2017, tasa)
print(top_crecimiento)
#> # A tibble: 10 × 5
#> centro_pob distrito pob_2007 pob_2017 tasa
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 SANFORTUNIA VELILLE 15 1,540 58.9
#> 2 HUARCA ESPINAR 10 244 37.6
#> 3 SAN MIGUEL QUELLOUNO 15 239 31.9
#> 4 SAN LUIS PISAC 11 150 29.9
#> 5 QQUECHASNIYOC ANDAHUAYLILLAS 19 259 29.8
#> 6 CCANCCAU LARES 18 238 29.5
#> 7 ROYAL INCA PISAC 18 222 28.6
#> 8 CONDEBAMBA ALTA-CONDEBAMBA BAJA SAYLLA 96 1,182 28.5
#> 9 LLAYCHU PAUCARTAMBO 29 342 28.0
#> 10 JANAC CHUQUIBAMBA LAMAY 19 218 27.6
# Centros poblados con mayor decrecimiento
top_decrecimiento <- ccpp_cusco |>
arrange(tasa) |>
head(10) |>
st_drop_geometry() |>
select(centro_pob, distrito, pob_2007, pob_2017, tasa)
print(top_decrecimiento)
#> # A tibble: 10 × 5
#> centro_pob distrito pob_2007 pob_2017 tasa
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 PUERTO MAYO PICHARI 460 151 -10.5
#> 2 POYENTIMARI ECHARATE 645 265 -8.51
#> 3 HUALLA YANATILE 667 280 -8.31
#> 4 SELVA ALEGRE VILCABAMBA 366 154 -8.29
#> 5 TIRINCAVINI PICHARI 370 160 -8.04
#> 6 PUCUTO HUARO 533 241 -7.63
#> 7 SUYO YANATILE 460 213 -7.41
#> 8 ANTIGUO SAN CRISTOBAL PICHARI 353 166 -7.27
#> 9 CCOYO SANTO TOMAS 396 187 -7.23
#> 10 URAYPAMPA PAMPA ANZA SICUANI 401 193 -7.05Análisis por clasificaciones
Por tipo de capital
ccpp_cusco |>
st_drop_geometry() |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
group_by(capital) |>
summarise(
n_centros = n(),
pob_total_2017 = sum(pob_2017, na.rm = TRUE),
tasa_promedio = mean(tasa, na.rm = TRUE),
tasa_mediana = median(tasa, na.rm = TRUE)
)
#> # A tibble: 4 × 5
#> capital n_centros pob_total_2017 tasa_promedio tasa_mediana
#> <chr> <int> <dbl> <dbl> <dbl>
#> 1 Departamental 1 111930 0.51 0.51
#> 2 Distrital 99 466653 1.33 1.03
#> 3 No es capital 725 225847 0.949 -0.22
#> 4 Provincial 12 164388 1.87 1.62Por clasificación urbano-rural
ccpp_cusco |>
st_drop_geometry() |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
group_by(urb_rural) |>
summarise(
n_centros = n(),
pob_total_2017 = sum(pob_2017, na.rm = TRUE),
tasa_promedio = mean(tasa, na.rm = TRUE),
tasa_mediana = median(tasa, na.rm = TRUE)
)
#> # A tibble: 2 × 5
#> urb_rural n_centros pob_total_2017 tasa_promedio tasa_mediana
#> <chr> <int> <dbl> <dbl> <dbl>
#> 1 RURAL 794 290491 0.898 -0.09
#> 2 URBANA 43 678327 3.02 2.06Por región natural
ccpp_cusco |>
st_drop_geometry() |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
group_by(region, tc_catg) |>
summarise(
n_centros = n(),
pob_total_2017 = sum(pob_2017, na.rm = TRUE),
tasa_promedio = mean(tasa, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 4 × 5
#> region tc_catg n_centros pob_total_2017 tasa_promedio
#> <chr> <chr> <int> <dbl> <dbl>
#> 1 Selva NEGATIVO 70 45942 -3.20
#> 2 Selva POSITIVO 57 49275 6.28
#> 3 Sierra NEGATIVO 342 161791 -2.07
#> 4 Sierra POSITIVO 368 711810 3.85Visualizaciones
Mapa de centros poblados por categoría de crecimiento
ccpp_cusco |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
ggplot() +
geom_sf(aes(color = tc_catg, size = pob_2017), alpha = 0.6) +
scale_color_manual(
values = c("POSITIVO" = "darkgreen", "NEGATIVO" = "darkred"),
name = "Crecimiento"
) +
scale_size_continuous(
name = "Población 2017",
range = c(0.5, 5),
labels = scales::comma
) +
labs(
title = "Centros Poblados del Departamento de Cusco",
subtitle = "Tasa de Crecimiento Poblacional 2007-2017",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal() +
theme(
legend.position = "right",
plot.title = element_text(face = "bold", size = 14),
plot.subtitle = element_text(size = 11)
)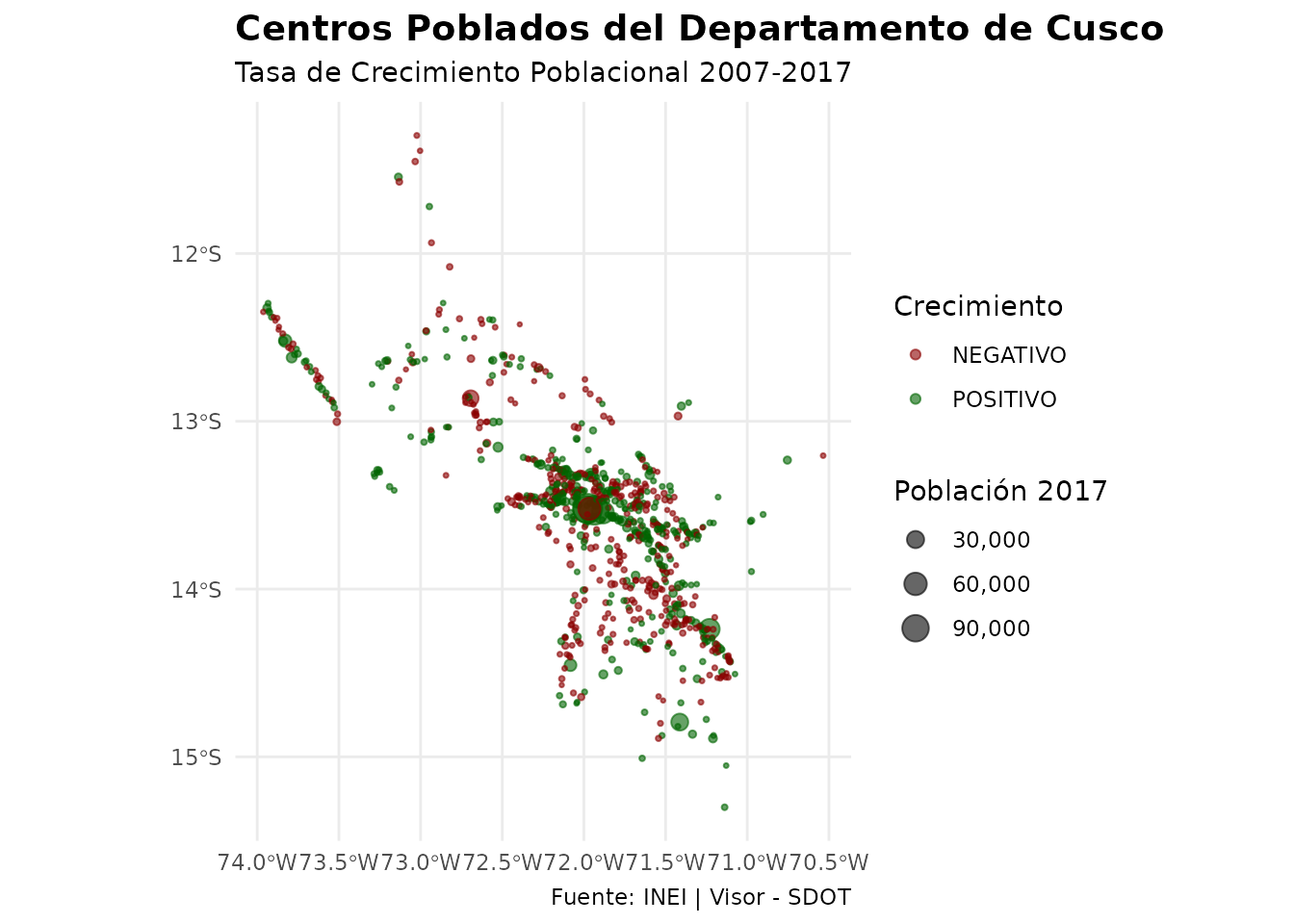
Centros poblados del departamento de Cusco coloreados por categoría de crecimiento (positivo/negativo)
Centros poblados urbanos
ccpp_urbanos <- ccpp_cusco |> filter(urb_rural == "URBANA")
ccpp_urbanos |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
ggplot() +
geom_sf(aes(color = tasa, size = pob_2017), alpha = 0.7) +
scale_color_gradient2(
low = "red",
mid = "yellow",
high = "darkgreen",
midpoint = 0,
name = "Tasa (%)"
) +
scale_size_continuous(
name = "Población 2017",
range = c(2, 8),
labels = scales::comma
) +
labs(
title = "Centros Poblados Urbanos - Cusco",
subtitle = "Tasa de Crecimiento Poblacional 2007-2017",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal()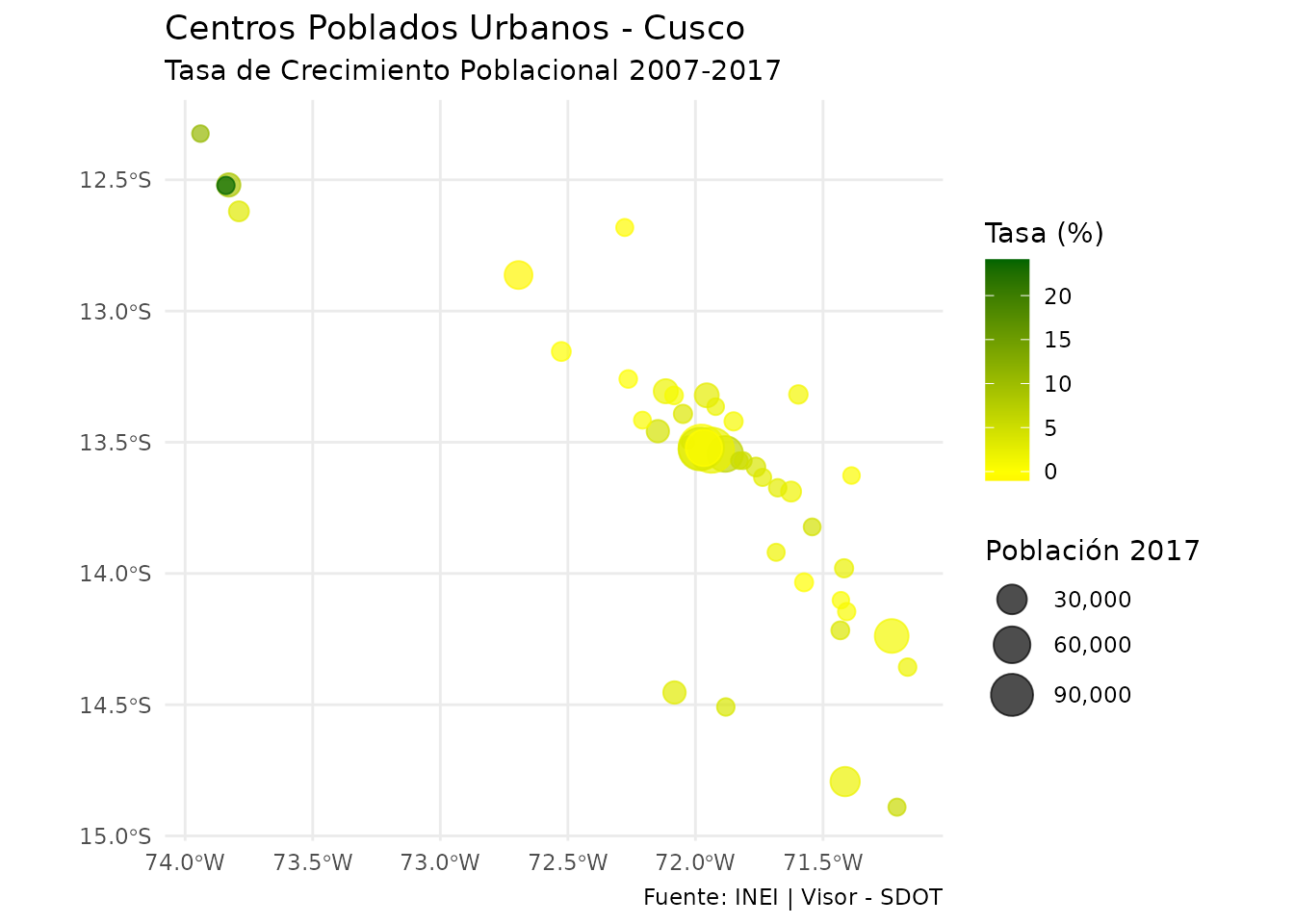
Centros poblados urbanos con gradiente de color según tasa de crecimiento
Top 20 por población
top_poblados <- ccpp_cusco |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
arrange(desc(pob_2017)) |>
head(20)
ggplot(top_poblados) +
geom_sf(aes(size = pob_2017, color = tasa), alpha = 0.7) +
geom_sf_text(
aes(label = centro_pob),
size = 2.5,
nudge_y = 0.05,
check_overlap = TRUE
) +
scale_size_continuous(
name = "Población 2017",
range = c(3, 15),
labels = scales::comma
) +
scale_color_gradient2(
low = "red",
mid = "yellow",
high = "darkgreen",
midpoint = 0,
name = "Tasa (%)"
) +
labs(
title = "Top 20 Centros Poblados por Población",
subtitle = "Departamento de Cusco - Censo 2017",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal()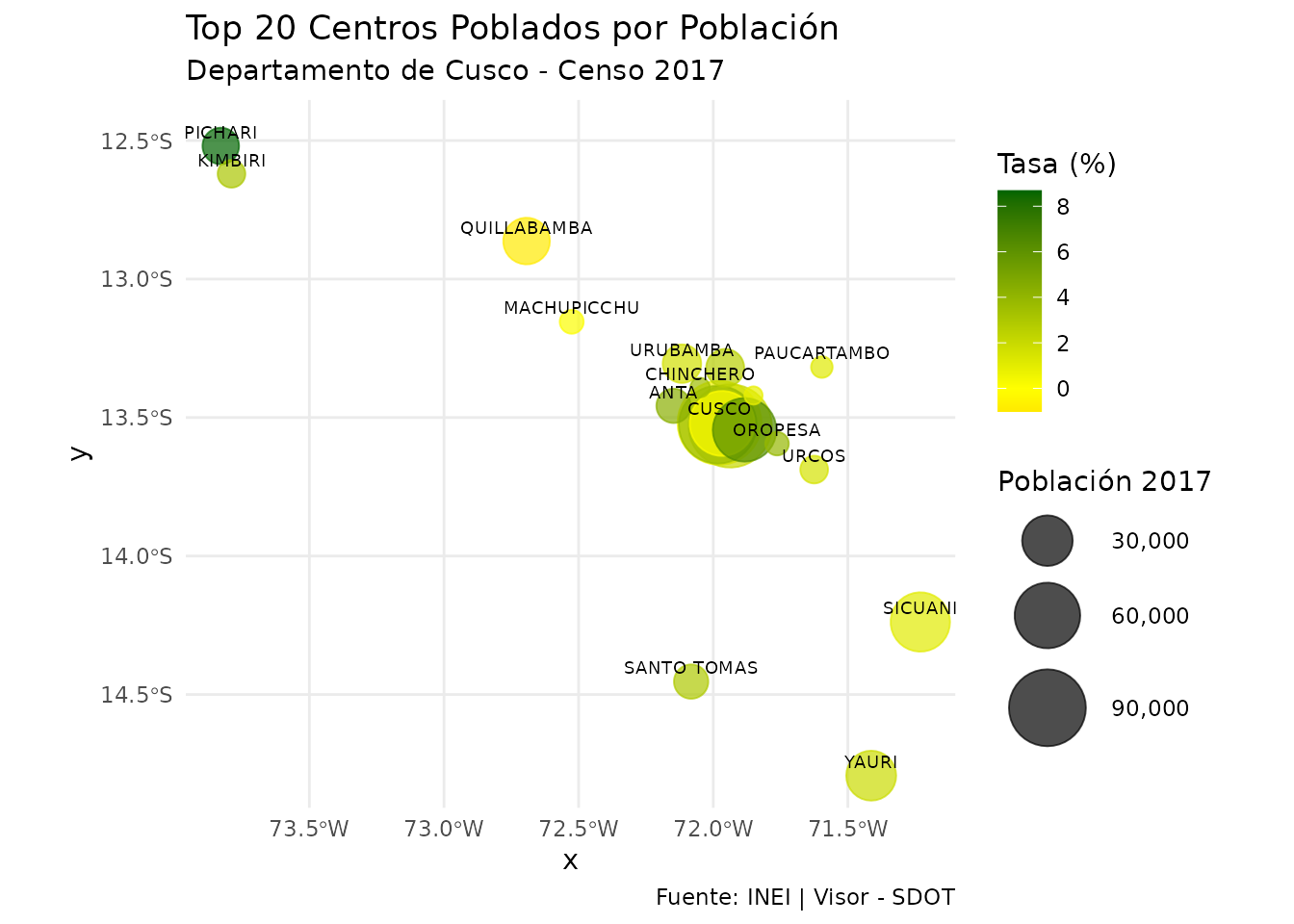
Los 20 centros poblados más grandes de Cusco
Boxplot por clasificación urbano-rural
ggplot(ccpp_cusco, aes(x = urb_rural, y = tasa, fill = urb_rural)) +
geom_boxplot(alpha = 0.7, outlier.alpha = 0.3) +
scale_fill_brewer(palette = "Set2") +
labs(
title = "Distribución de Tasas de Crecimiento Poblacional",
subtitle = "Por clasificación urbano/rural - Departamento de Cusco",
x = "Clasificación",
y = "Tasa de Crecimiento (%)",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal() +
theme(legend.position = "none")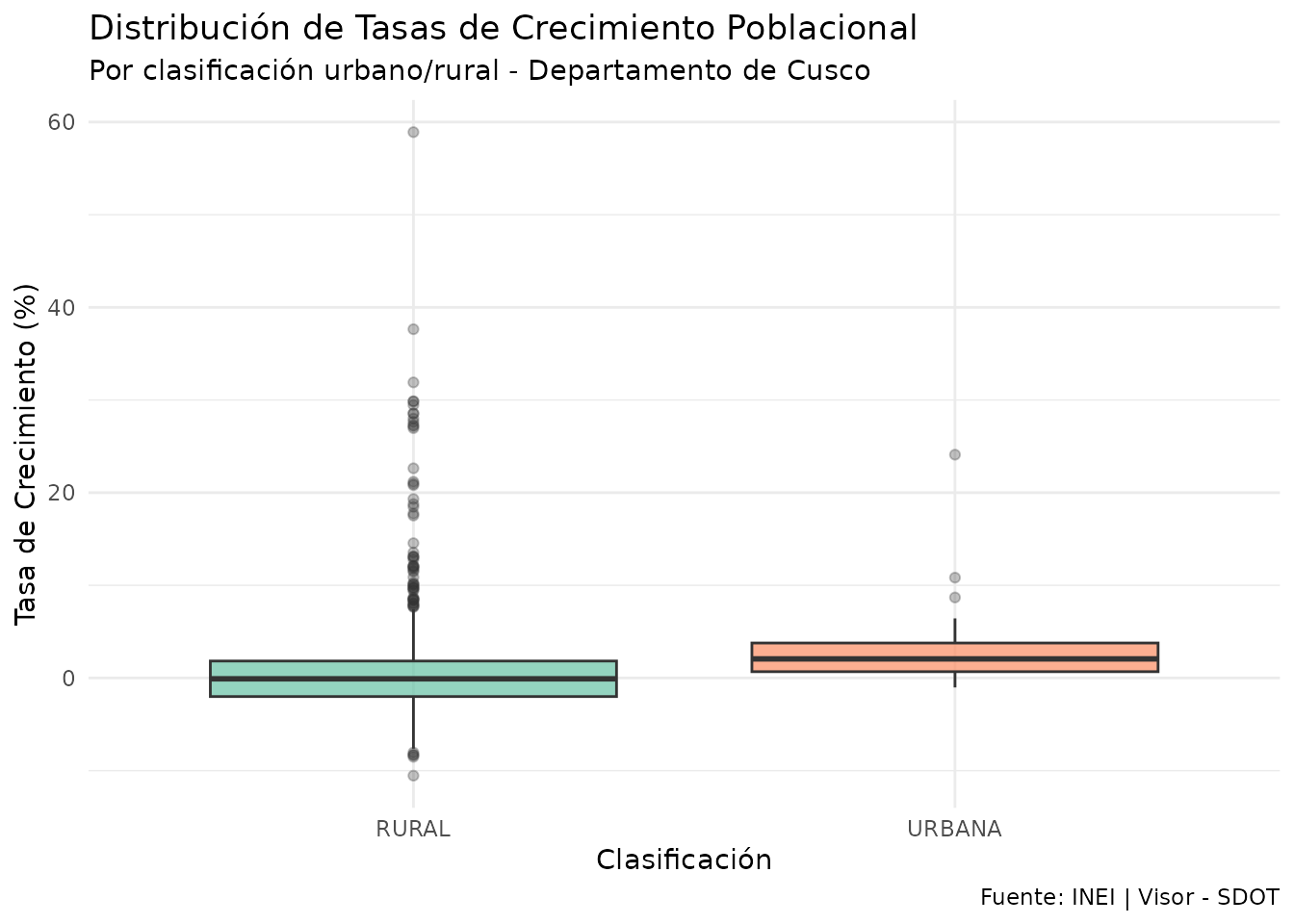
Distribución de tasas de crecimiento por clasificación urbano/rural
Histograma de tasas
ggplot(ccpp_cusco, aes(x = tasa, fill = tc_catg)) +
geom_histogram(bins = 50, alpha = 0.7) +
scale_fill_manual(
values = c("POSITIVO" = "darkgreen", "NEGATIVO" = "darkred"),
name = "Categoría"
) +
labs(
title = "Distribución de Tasas de Crecimiento Poblacional",
subtitle = "Departamento de Cusco (2007-2017)",
x = "Tasa de Crecimiento (%)",
y = "Número de Centros Poblados",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal()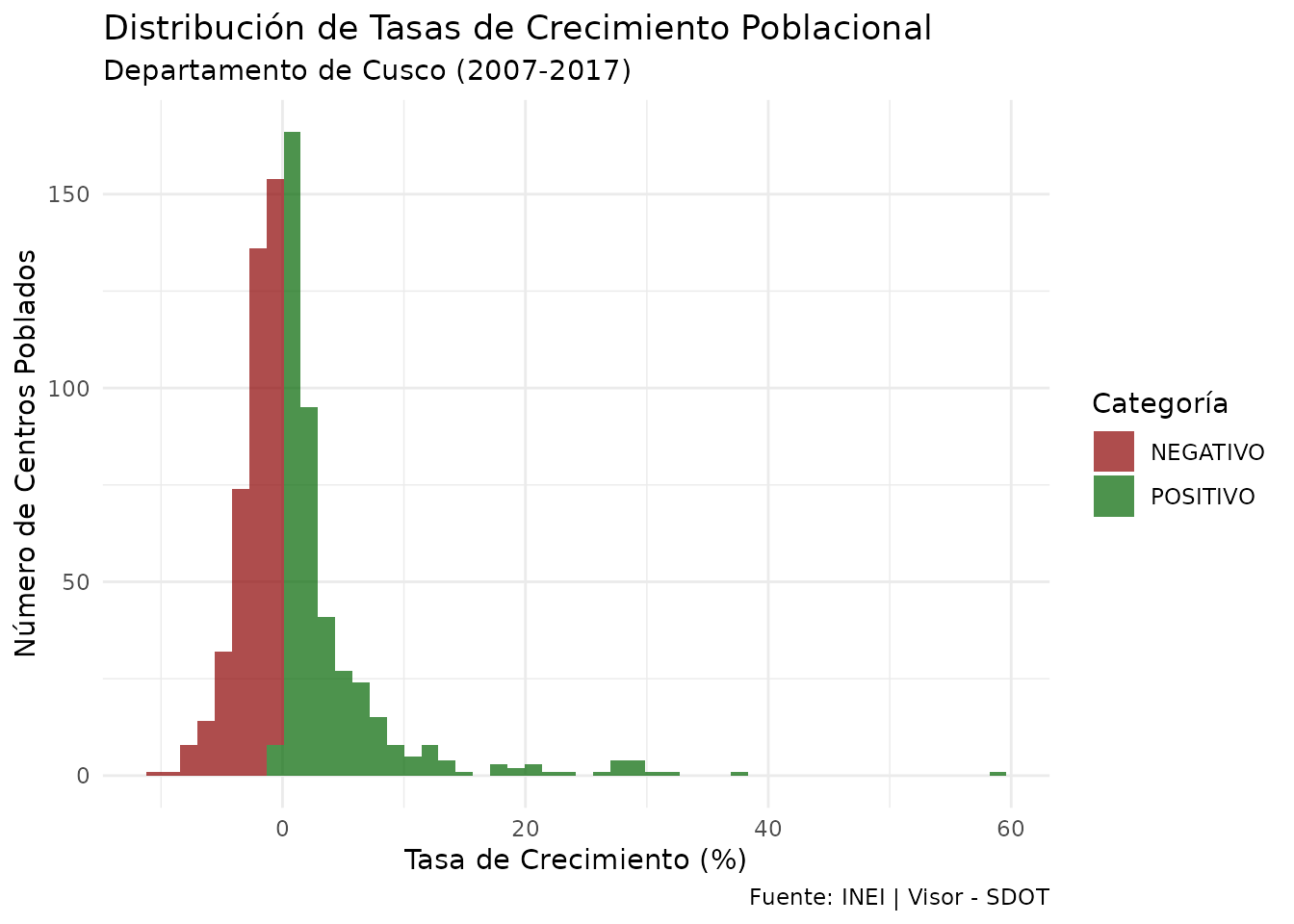
Distribución de frecuencias de las tasas de crecimiento
Evolución poblacional 2007-2017
ccpp_cusco |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
ggplot(aes(x = pob_2007, y = pob_2017, color = tc_catg)) +
geom_point(alpha = 0.5, size = 2) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed", color = "gray50") +
scale_x_log10(labels = scales::comma) +
scale_y_log10(labels = scales::comma) +
scale_color_manual(
values = c("POSITIVO" = "darkgreen", "NEGATIVO" = "darkred"),
name = "Crecimiento"
) +
labs(
title = "Evolución Poblacional 2007-2017",
subtitle = "Departamento de Cusco (escala logarítmica)",
x = "Población 2007",
y = "Población 2017",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal()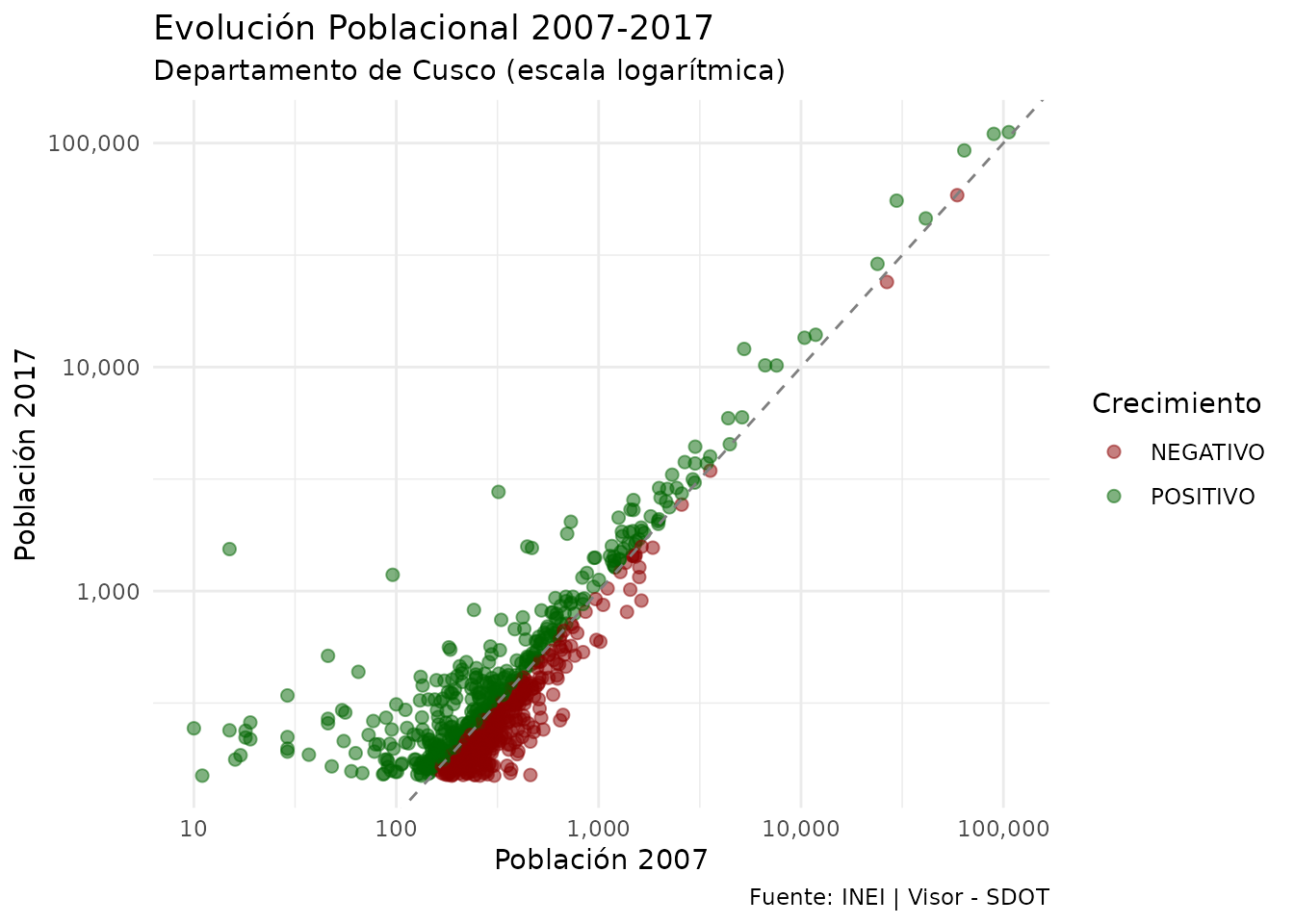
Relación entre población 2007 y 2017 (escala logarítmica)
Interpretación: Los puntos por encima de la línea diagonal representan centros poblados que crecieron, mientras que los puntos por debajo perdieron población.
Integración con otras capas
Combinar con límites distritales
Una de las ventajas del paquete rsdot es que permite
integrar fácilmente diferentes capas de información espacial:
# Obtener límites distritales
distritos_cusco <- get_distritos(departamento = "CUSCO")
# Mapa combinado
ggplot() +
geom_sf(data = distritos_cusco, fill = NA, color = "gray70", linewidth = 0.3) +
geom_sf(
data = ccpp_cusco |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
),
aes(color = tc_catg, size = pob_2017),
alpha = 0.6
) +
scale_color_manual(
values = c("POSITIVO" = "darkgreen", "NEGATIVO" = "darkred"),
name = "Crecimiento"
) +
scale_size_continuous(
name = "Población 2017",
range = c(0.5, 5),
labels = scales::comma
) +
labs(
title = "Centros Poblados y Límites Distritales",
subtitle = "Departamento de Cusco",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal()
Centros poblados sobre límites distritales de Cusco
Análisis agregado por distrito
Calcular estadísticas por distrito
ccpp_por_distrito <- ccpp_cusco |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
st_drop_geometry() |>
group_by(distrito) |>
summarise(
n_centros_poblados = n(),
pob_total_2017 = sum(pob_2017, na.rm = TRUE),
pob_total_2007 = sum(pob_2007, na.rm = TRUE),
tasa_promedio = mean(tasa, na.rm = TRUE),
n_positivo = sum(tc_catg == "POSITIVO", na.rm = TRUE),
n_negativo = sum(tc_catg == "NEGATIVO", na.rm = TRUE)
) |>
arrange(desc(pob_total_2017))
head(ccpp_por_distrito, 10)
#> # A tibble: 10 × 7
#> distrito n_centros_poblados pob_total_2017 pob_total_2007 tasa_promedio
#> <chr> <int> <dbl> <dbl> <dbl>
#> 1 CUSCO 6 113359 107506 2.23
#> 2 SAN SEBASTIAN 7 112365 91597 2.73
#> 3 SANTIAGO 6 94258 65516 0.492
#> 4 WANCHAQ 1 58541 59134 -0.1
#> 5 SAN JERONIMO 4 56157 30439 2.06
#> 6 SICUANI 18 50765 46227 -0.263
#> 7 ESPINAR 3 30935 24576 16.5
#> 8 SANTA ANA 6 25229 28088 -2.63
#> 9 PICHARI 16 20124 10078 2.03
#> 10 ANTA 30 19918 15118 1.57
#> # ℹ 2 more variables: n_positivo <int>, n_negativo <int>Mapa coroplético por distrito
# Unir estadísticas con geometrías
distritos_con_datos <- distritos_cusco |>
left_join(ccpp_por_distrito, by = c("nombdist" = "distrito"))
# Mapa coroplético
ggplot(distritos_con_datos) +
geom_sf(aes(fill = n_centros_poblados), color = "white", linewidth = 0.2) +
scale_fill_viridis_c(
option = "plasma",
name = "N° Centros\nPoblados"
) +
labs(
title = "Número de Centros Poblados por Distrito",
subtitle = "Departamento de Cusco",
caption = "Fuente: INEI | Visor - SDOT"
) +
theme_minimal()
Número de centros poblados por distrito en Cusco
Casos de uso avanzados
Identificar áreas de alta concentración poblacional
# Centros poblados con más de 5,000 habitantes
grandes_centros <- ccpp_cusco |>
mutate(pob_2017 = as.numeric(str_remove(pob_2017, ","))) |>
filter(pob_2017 > 5000) |>
arrange(desc(pob_2017))
cat("Centros poblados con más de 5,000 habitantes:", nrow(grandes_centros), "\n")
#> Centros poblados con más de 5,000 habitantes: 15Análisis de centros poblados candidatos para creación distrital
Los centros poblados con crecimiento positivo sostenido pueden ser candidatos para análisis de creación distrital:
candidatos <- ccpp_cusco |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
filter(
tc_catg == "POSITIVO",
tasa > 2, # Crecimiento mayor a 2% anual
pob_2017 > 3000 # Población mínima
) |>
st_drop_geometry() |>
select(centro_pob, distrito, pob_2007, pob_2017, tasa, capital) |>
arrange(desc(tasa))
head(candidatos, 10)
#> # A tibble: 10 × 6
#> centro_pob distrito pob_2007 pob_2017 tasa capital
#> <chr> <chr> <dbl> <dbl> <dbl> <chr>
#> 1 PICHARI PICHARI 5236 12050 8.69 Distrital
#> 2 SAN JERONIMO SAN JERONIMO 29678 55335 6.43 Distrital
#> 3 ANTA ANTA 6652 10182 4.35 Provincial
#> 4 OROPESA OROPESA 3001 4411 3.93 Distrital
#> 5 SANTIAGO SANTIAGO 64075 92729 3.77 Distrital
#> 6 YANAOCA YANAOCA 2308 3307 3.66 Provincial
#> 7 CHINCHERO CHINCHERO 2664 3765 3.52 Distrital
#> 8 KIMBIRI KIMBIRI 4369 5913 3.07 Distrital
#> 9 SANTO TOMAS SANTO TOMAS 7575 10170 2.99 Provincial
#> 10 CALCA CALCA 10413 13519 2.64 ProvincialComparación entre capitales y no capitales
ccpp_cusco |>
mutate(
es_capital = ifelse(capital == "No es capital", "No", "Sí"),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
) |>
st_drop_geometry() |>
group_by(es_capital) |>
summarise(
n = n(),
tasa_promedio = mean(tasa, na.rm = TRUE),
pob_promedio = mean(pob_2017, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 2 × 4
#> es_capital n tasa_promedio pob_promedio
#> <chr> <int> <dbl> <dbl>
#> 1 No 725 0.949 312.
#> 2 Sí 112 1.38 6634.Consejos y mejores prácticas
1. Manejo de datos
Al trabajar con población, es importante convertir las variables numéricas correctamente:
# Convertir población de character a numeric
ccpp_clean <- ccpp_cusco |>
mutate(
pob_2007 = as.numeric(str_remove(pob_2007, ",")),
pob_2017 = as.numeric(str_remove(pob_2017, ","))
)2. Filtrado eficiente
Para análisis por región o tipo:
# Filtrar por múltiples condiciones
ccpp_sierra_urbano <- ccpp_cusco |>
filter(
region == "Sierra",
urb_rural == "URBANA"
)3. Exportar resultados
Guardar los datos procesados para uso posterior:
# Exportar a GeoPackage
st_write(ccpp_cusco, "centros_poblados_cusco.gpkg", delete_dsn = TRUE)
# Exportar tabla sin geometría
ccpp_cusco |>
st_drop_geometry() |>
write.csv("centros_poblados_cusco.csv", row.names = FALSE)4. Sistema de caché
La función almacena automáticamente los datos descargados:
# Primera ejecución: descarga desde OSF
ccpp1 <- get_centros_poblados_crecimiento(departamento = "CUSCO")
# Segunda ejecución: usa caché (más rápido)
ccpp2 <- get_centros_poblados_crecimiento(departamento = "CUSCO")
# Forzar nueva descarga si necesitas actualizar datos
ccpp3 <- get_centros_poblados_crecimiento(
departamento = "CUSCO",
force_update = TRUE
)Conclusiones
La función get_centros_poblados_crecimiento() facilita
el acceso a datos valiosos sobre la dinámica poblacional del Perú a
nivel de centros poblados. Los principales hallazgos de este análisis
incluyen:
Diversidad de patrones: Existen centros poblados con crecimiento muy acelerado y otros en decrecimiento
Diferencias urbano-rural: Las áreas urbanas tienden a mostrar patrones de crecimiento diferentes a las rurales
Utilidad para planificación: Los datos son fundamentales para análisis de creación distrital y planificación territorial
Integración de datos: La función se integra perfectamente con otras funciones del paquete para análisis espaciales más complejos